[Aggregation&Subquery] 1. COUNT()로 레코드 개수 구하기
반갑습니다!
이번 포스트부터는 count(), avg(), sum() 등의 집계함수들과
GROUP BY 키워드 같은 그룹화와 관련된 내용들을 살펴보겠습니다 ^^
이번부터 사용할 샘플 데이터셋은
customers 테이블과 orders 테이블 두 개입니다!
샘플 파일 첨부하겠습니다 ^^

먼저 customers 테이블입니다
first_name, last_name, email 세 개의 필드가 있고
레코드의 개수는 총 100개입니다 ^^
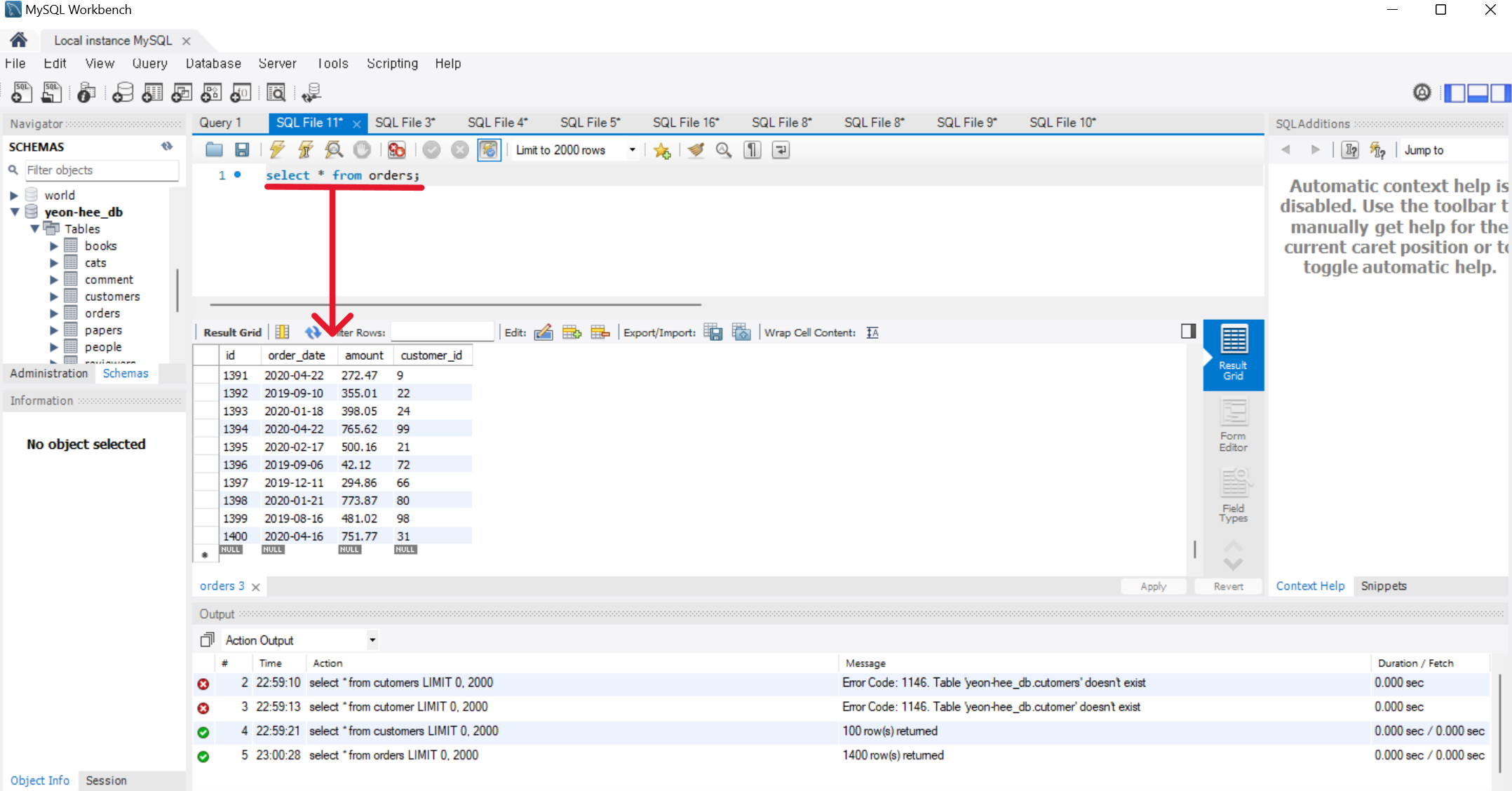
orders 테이블입니다
order_date, amount, customer_id 세 개의 필드가 있고
레코드의 개수는 총 1400개입니다 ^^
가장 간단하게,
특정 테이블의 레코드 개수가 몇 개인지
count() 함수를 이용해서 조회를 해볼까요?

해당 테이블의 id 컬럼을 조회했을 때 가장 마지막 번호가 1400이었는데요
count() 함수를 이용하여 레코드의 갯수를 세어보니 1400이 출력되었습니다 ^^
count() 함수의 파라미터로 특정 컬럼 이름을 넣어주시면 되겠습니다
이미지와 같이 모든 컬럼(*)에 대해서도 물론 가능하구요 ^^!
본 예시는 레코드의 갯수를 파악하기가 너무나 쉽기 때문에
당연한 결과에 대해서 별다른 유용성이 잘 안 느껴질 수도 있습니다
근데 특정 조건으로 조회를 했을 경우에는 컬럼의 id값이 예시와 같이
1부터 순서대로 쭉 나열되지 않기 때문에 추산하기가 어렵습니다
이럴 때 count() 함수를 사용하면 파악하기가 수월하죠 ^^

조건을 추가하여 조회했습니다
레코드들 중에는 2019년에 해당하는 것들, 2020년에 해당하는 것들이 섞여있는데요
과연 2020년에 해당하는 것들은 몇 개일까요?
WHERE구를 이용하여 조건조회를 했지만 레코드를 하나 하나 세지 않는 이상
한 눈에 보기에 몇 개인지 감이 오지 않습니다
이 때 COUNT() 함수를 사용하면 쉽게 파악이 가능하죠?

총 1400개의 데이터 중에서 해당 조건을 만족하는
데이터의 개수는 720개임을 쉽게 알 수 있겠습니다 ^^

이번엔 두 테이블을 JOIN 연산으로 합친 다음에
그룹화를 하여 각 유저별 order_count와 amount_average 값을 컬럼으로 추가하여 출력했습니다 ^^
상기 SQL문에, 아직 포스트에서 다루지 않은 내용들인
AVG() 함수와 GROUP BY, HAVING 키워드가 포함되어 있는데요
바로 다음 포스트부터 순서대로 다 살펴볼 내용들이기 때문에 미리 익숙해지기 위한 마음으로,
그리고 복잡한 예시 제시를 위해서 미리 사용했습니다 ^^
이 데이터를 amoun_avg 컬럼을 기준으로 내림차순 정렬 했을 때,
amount 평균 값이 300 이상인 데이터의 개수는 총 몇 개일까요?

서브 쿼리를 이용하여 count() 함수로
해당 조건 조회에 대한 레코드의 개수를 세어보니 89개라고 하네요 ^^
count() 함수의 편의성을 보여드리기 위해서
일부러 쿼리문을 조금 복잡하게 구성했습니다 ^^;;
※ 참고 ※
이처럼 레코드의 개수를 집계할 때 편리하게 사용이 가능한데요
여기서 주의사항이 있습니다
count() 함수의 파라미터로 애스터리스크(*)를 넣어주시면
모든 행을 계산하라는 의미이기 때문에,
NULL 값 포함 여부와 상관 없이 모든 레코드의 개수를 계산합니다
즉, count(*)는 NULL값 포함여부와 상관 없이 무조건 전체 행 계산입니다 ^^
근데 특정 컬럼을 지정해서 레코드의 갯수를 집계하는 경우에는,
NULL값이 포함되어 있는 경우 집계의 대상에서 제외가 됩니다 ^^
그렇기 때문에 테이블의 레코드들 가운데,
특정 필드의 값이 NULL 상태인 데이터가 있다면
전체 행의 개수를 집계했을 때의 결과값과 상이할 수 있습니다!
이번 포스트에서는 count() 함수에 대해 살펴보았습니다!
다음 포스트에서는 count() 함수 이외의
avg(), sum() 등의 다른 집계함수에 대해서 알아보겠습니다 ^^!